
As a food safety professional one must be aware of the plethora of threats to ensure a robust and safe food supply chain. Essential global food safety data needs to be collected, translated, and enriched relating to food recalls and border rejections; price data on agricultural commodities and animal products; news items related to food safety; fraud cases; laboratory testing performed by Food Safety Authorities worldwide, inspections and warning letters on food companies’ plants and premises, and country-level indicators concerning food safety – the list goes on.
However, collecting and processing the data is one part of the puzzle. It is all well and good being aware of certain aspects of the food supply chain but it is another to make intelligent insights and decisions. This can only be done through a process called data orchestration.
The importance of data orchestration
The process of data orchestration – also known as ETL workflows (extract transform load workflows) – is the automation of data-driven processes from end-to-end including preparing data, making decisions based on that data, and taking actions based on those decisions to ensure a high standard of food safety across the global supply chain.
So, what are the keys to effective data orchestration, what tools can we use and how can we synchronize the data flows?
The first step for the DevOps team to deploy a stack – a mass of different data relating to the food supply chain. There are many tools out there that can be used for this, with Apache Airflow and Spotify’s Luigi among the top contenders for a developer to use.
Our initial choice was to use a tool called ‘cronjobs;’ a time-based job scheduler. We then automate data processes using developer ‘scripts’ called ‘Bash Scripts’ and ‘crontab -e commands.’
Every data source we track had its own dedicated directory in our processing servers – also known as the ‘backend’ – and each of these directories contain a run.sh script. This script is responsible for running each and every workflow and is triggered by the crontab.
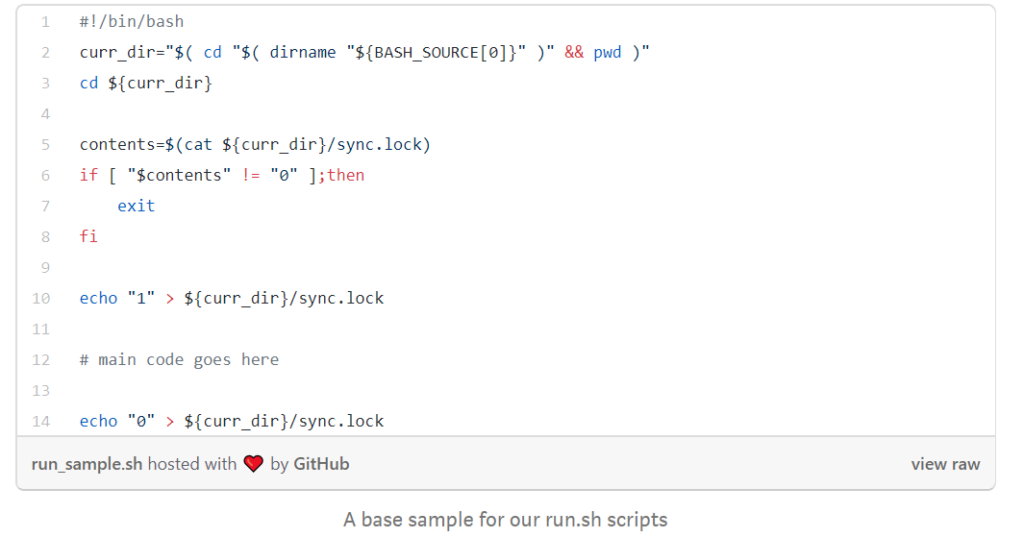
We then populate these scripts with lines of code in our dedicated servers and this is where the magic of data orchestration happens.
Firstly, we extract the data that we want to analyze. Then we check if the script responsible for the data extraction has completed its work i.e. data validation, by checking the respective ‘lockfile.’ Finally, we update the lockfile for the next trigger script.
Depending on the data source, translation endpoint triggering scripts may be present – i.e. putting the data into context and incorporating it into an assigned format e.g. an excel document, a file, a folder etc. Text mining – also known as data mining or text classification workflows – breaking down the data into categories and groups – may take place with their respective scripts.
After we have completed the collection and processing of each data record, we record the new data on our internal Content Management System (Drupal). Finally, we transfer the data files using a SFTP – a secure protocol for file transfer – and upload the respective transformed and enriched data records.
For leveraging data that has already been processed, we use a tool called MongoDB: where all the raw data is stored, along with the timestamp of when it was collected and a flag signifying whether or not a record has already been processed.
How to ensure data orchestration is seamless
To ensure that data orchestration is executed as quickly and efficiently as possible, ETL workflows should be deployed when new data is present. For this to be done we need to identify the speed at which workflows can be dispatched.
At the same time, we need to be conscious of server ‘stress levels.’ If ETLs are deployed when intensive tasks are under way it will reduce the speed of the data orchestration and potentially lead to an overload.
Finally, be aware of firewalls these can disrupt the data flow when transferring data from one place to another including specific permissions required. In addition, IT security including fail2ban: that bans IPs that contain malicious signs, and overall crawler traffic that prevents malicious bot traffic, can also affect the workflows capabilities.
Splitting the workload into Atomic Operations – which in layman terms means the ability to execute workflows without interruption – ensures that there is no data loss and the correct permissions and authorisation are in place, to optimise the ETL workflow.
Using data orchestration to make intelligent decisions
Once we have completed data orchestration, the insights that we yield help food safety professionals across the globe make informed, intelligent decisions to keep food safe.
If you’d like to discover how FOODAKAI can help your Food Safety & Quality team prevent product recalls by monitoring & predicting risks, schedule a call with us!