
Ensuring global food safety depends on data. There is data concerning food recalls and border rejections, data pertaining to a huge amount of raw ingredients and commodities, and data unpacking all the possible hazards behind a food safety incident.
When a food safety incident occurs somewhere in a global supply chain, whether on a market or a customs level, simply gaining access to that top-level information is not enough to truly understand the repercussions. What about the product brand that was recalled? Which was the company behind the recall? And if you dive even deeper you also need to make sure you also understand the company’s involvement in the incident. Was it the manufacturer, or the packer? Or was it possibly the importer or the trader?
In other words, accessing comprehensive, reliable data in real-time — and being able to properly analyse and harness that data — is critical for ensuring food safety amid increasingly complex, dynamic and international supply chains. How can the food industry achieve this?
Data extraction, enrichment and presentation
The first challenge is one of access — that is, actually identifying the relevant data sources for a particular food safety incident, and gaining access to them. And although a simple Google search: “Food Safety Authority in XX” may prove successful in some cases, language and local regulation can make this more difficult in certain countries or jurisdictions.
Even once we have identified the relevant sources, actually extracting the data we need may be further complicated. A simple crawl will suffice in many cases, but there are still plenty of data sources in Africa and Asia where there are restrictions.
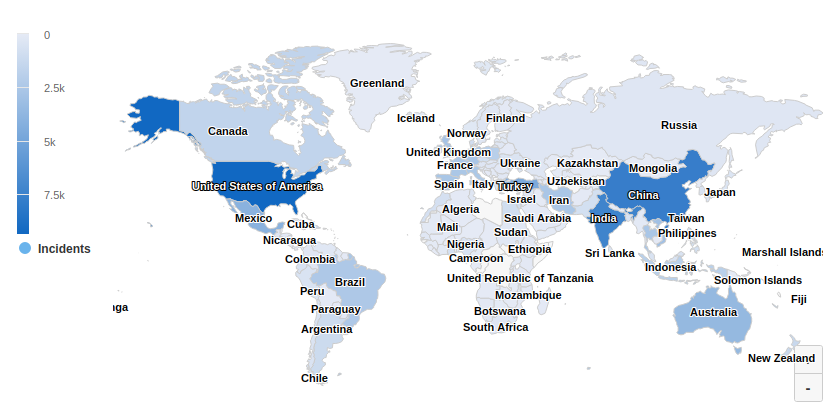
However, once we have overcome this and extracted the data we need, this newly acquired information is likely to exist across various different formats and languages. A number of directories full of htmls, pdfs and xls spreadsheets await processing. The next step, then, is to translate these data into a common language such as English.
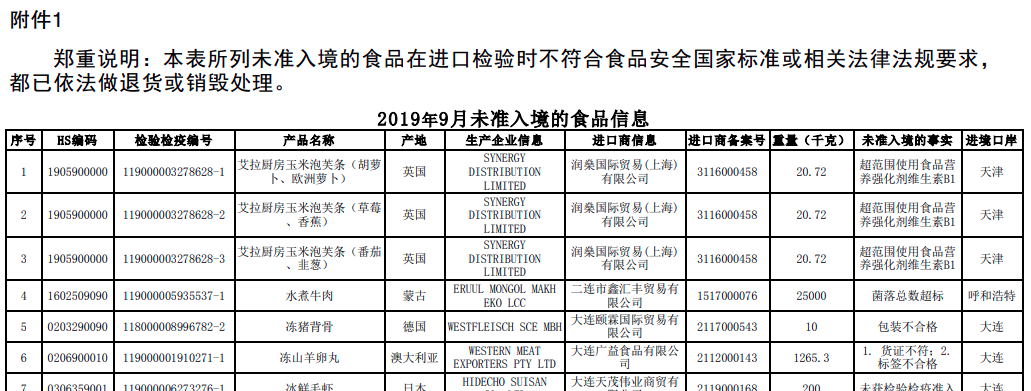
With this information at our disposal, we can begin identifying some of the core factors behind the food safety incident. These include:
- the date of the food safety incident;
- the reason behind the recall;
- the product brand involved;
- its main ingredient;
- as many of the companies involved as possible.
We can achieve this through a number of different state-of-the-art tools and technologies. For example, Named Entity Recognition (NER) can be used to locate and classify information into pre-defined categories such as organisation names or locations. Natural Language Processing (NLP) tools can be used to analyse large volumes of natural language data and transform it into useful information. Ultimately, the goal is to annotate each food safety incident with as much useful, enriched information as possible.
Nevertheless, the automatic data enrichment performed by these tools and algorithms is not enough on its own. It is still necessary to bring a food safety expert into the process, to manually review all the extracted information and either correct it or approve its publishing.
Another important point to consider is the possibility of the same incident being announced by multiple different countries and Food Safety Authorities — for example, the Rapid Alert System for Food and Feed (RASFF) which operates across the EU, might alert to the same incident as a member state’s individual authority. It is important, therefore, to be able to automatically identify such cases and suggest them to the food expert as possible duplicates. Should this suggestion prove valid, the relevant information must be merged, so that the analysis performed is statistically sound and has as many data properties as possible.
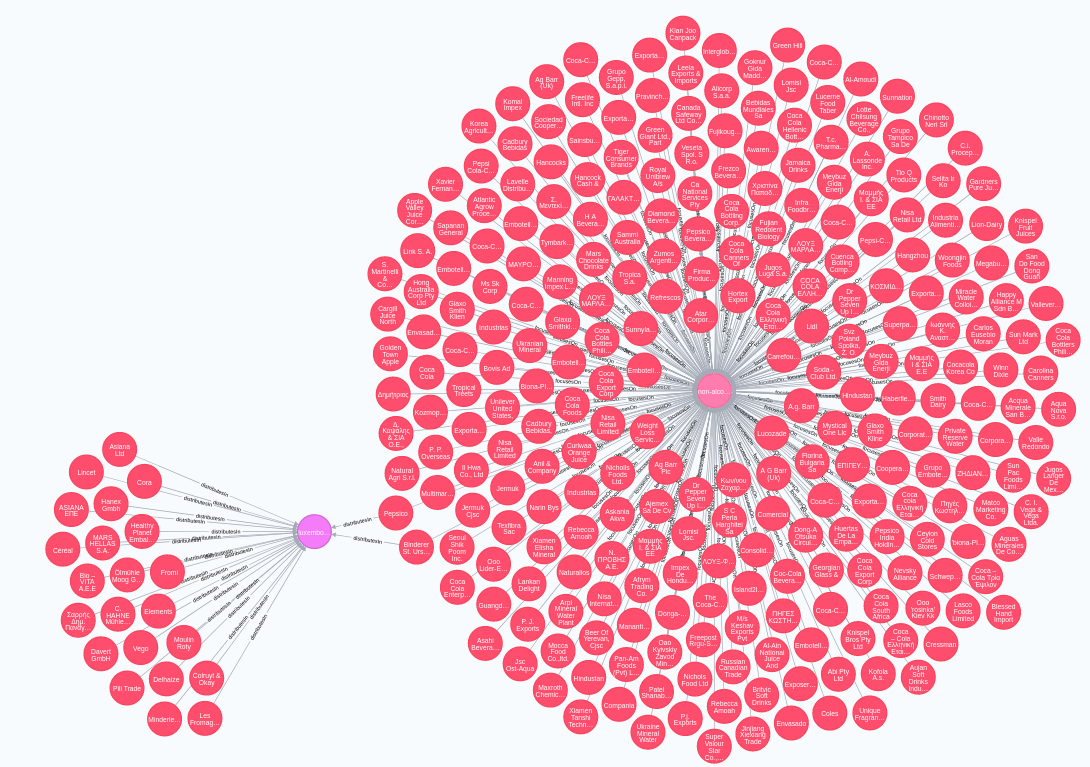
Now (finally) the data is ready to be visualised, analysed and correlated. From there, it can support intelligent decision-making and smart strategy across the food safety sector.
The role of FOODAKAI
And this is (part of) our everyday life in FOODAKAI! We are focused on continually identifying new sources of food safety information from across the globe, applying the most appropriate automatic analysis and annotation, in order for the curated data to be presented at and visualised by end users from all around the world.
Here, we have focused on the official sources of information from food safety authorities. Truly comprehensive and intelligent data-empowerment for the food safety sector requires further information sources too. Laboratory testing results, price data, country level indicators, consumer complaints, food (or animal) borne outbreaks, food consumption rates, production and trade indicators are also published throughout the world and can provide additional layers of enrichment and intelligence.
On our next post in this series we will dive deeper into these diverse data types, and explore how correlating them can further empower the food safety sector.
CONCLUSION
The food safety sector incorporates myriad different forms of data, published by multiple different organisations and authorities, all over the world. Applying state-of-the-art technology to this data can unlock new insights and intelligence, inform better decision-making, and generate a safer, smart food industry across the globe.
We have decided during this times to open up access to our global food safety data insights for all people taking care of producing, packaging, distributing and serving safe food to all of us so they can better understand the data insights value.