
It is no secret that making intelligent use of data is one of the most exciting — and important — evolutions in enterprise technology. COVID-19 has increased the need to access data and technology with social distancing and lockdown measures altering the working environment for all industries. It’s prominent now, more than ever, that the most successful organisations of the future will be those that can tap into the power of data to keep the global food supply chain safe.
Being able to identify hazards remotely and quickly is essential in a post-COVID-19 environment, with the majority of food professionals working from home or being gradually re-introduced into the workforce. By extracting and interpreting data with the right technology, we are able to identify the hazards behind a food recall to ensure that the global supply chain is kept safe — both the food which is in already in the supply chain and the food that is being prepared for distribution.

The importance of data in identifying hazards
Through harnessing open source data in real-time, we are able to understand and predict the severity of a food safety risk in the food supply chain relating to a raw material, ingredient or product.
To build up a picture of the food safety landscape, we begin by extracting and correlating information on food recalls at the local market level, border rejections and country indicators.
Information around food recalls and border rejections can tell us the date of the recall, reason for the recall i.e. the type of hazard, the main ingredient involved in the recall and border rejection, country of origin, and the country where the ingredient was distributed to.
At the same time, we can identify and process data around the food safety profile of each country, to provide an overview of the likelihood of food safety risk occurring within the supply chain. For example, information relating to the level of risk, prevalence of corruption, and the global food security index — the probability of a food safety incident by country.
Making sense of the data
The final step is to deploy all of these data insights into a correlation matrix, and by applying sophisticated algorithms we generate crucial information that can help to inform the food safety community of the current and future risks across the global supply chain.
By correlating variables such as country of origin and distribution with hazard and product categories, while applying machine learning or deep learning models to the data, we can predict food safety cases throughout the world.
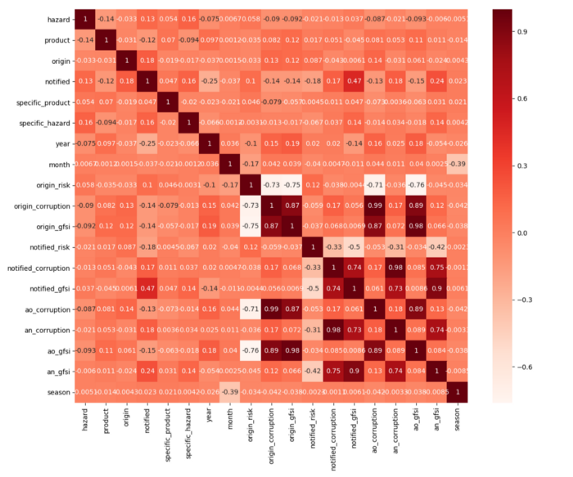
Data in action: predicting hazards of tomorrow
Before embarking on a data experiment to create actionable insights, it’s important to know the origin of the data and its authenticity — to ‘pre-process’ it, and to then interrogate the types of data that we correlate in a matrix.
Not all data is treated equal, and it’s the essential work of a data analyst to identity what is worth correlating and what is just ‘noise‘ i.e. irrelevant data.
Once we have the data insights it doesn’t end there. By drawing on the expertise of food scientists, we can enrich data with intelligence that even a machine would not reach on its own. By doing so, this enriched data can support informed, intelligent decision making across the food safety sector.
Organisations from across the industry need intelligent tailor-made data insights using both data and human expertise. This will allow for more accurate, comprehensive and dynamic insights — helping organisations to plan, prepare and respond to food safety risks across the global supply chain.
Don’t worry if the science behind our data analysis sounds overwhelming, our premium technology platform — FOODAKAI — enables food safety professionals of all levels to understand and interpret the data, which can provide crucial information to minimize food safety risks in your supply chain.
![]() “Funded with the support by European Commission, and more specifically the project CYBELE “FOSTERING PRECISION AGRICULTURE AND LIVESTOCK FARMING THROUGH SECURE ACCESS TO LARGE-SCALE HPC-ENABLED VIRTUAL INDUSTRIAL EXPERIMENTATION ENVIRONMENT EMPOWERING SCALABLE BIG DATA ANALYTICS” (Grant No. 825355)”
“Funded with the support by European Commission, and more specifically the project CYBELE “FOSTERING PRECISION AGRICULTURE AND LIVESTOCK FARMING THROUGH SECURE ACCESS TO LARGE-SCALE HPC-ENABLED VIRTUAL INDUSTRIAL EXPERIMENTATION ENVIRONMENT EMPOWERING SCALABLE BIG DATA ANALYTICS” (Grant No. 825355)”