
You will agree with me that predictive analytics for food safety needs plenty of science. I believe that it also needs an artistic touch as well. Not everyone will try to crack a food safety analytics problem in the same way. Building a food safety prediction machine requires quite a sophisticated approach for two main reasons.
Firstly, because it is not as simple as it seems.
Yes, there are plenty of public food safety data sets (like the European RASSF one or the various ones in the US FDA Data Dashboard) that someone can use to train and test an AI algorithm. There are also many open source machine learning and other algorithms that one can use.
But selecting, training and deploying an AI algorithm that can efficiently predict food safety events with high accuracy and confidence, can become quite a laborious task.
Secondly, because it is not clear how much you can rely upon it.
Yes, you can select and deploy a sophisticated machine learning algorithm so that it may predict accurately some of the product recalls that have already taken place. You may also combine public recall data with internal recalls to train an algorithm that will be tailor-made to a specific industry sector or supply chain.
But continuously monitoring and assessing an AI algorithm to ensure that it delivers reliable predictions and may support business critical decisions, is not the same with executing a one-off prediction experiment.
I have a strong opinion about how food safety predictive analytics should work.

In my PhD, I have experimented a lot with collaborative filtering, a family of ‘recommender system algorithms’ that try to predict what people are going to like. I have performed extensive training and testing of algorithms, using both synthetic and real-life data sets. I have studied which parameters seems to be working best in each problem setting, using the corresponding data sets. I have even developed an online system that helps data scientists in designing and executing such data analysis experiments.
Then, we have also devoted significant time and resources in Agroknow, investigating how AI algorithms may serve food safety prediction tasks. Our most recent work has been an extensive experiment that we have presented this year at the GFSI conference in Seattle. We have applied machine learning methods on a very large data set of historical food recalls and border rejections, trying to predict the food safety hazards and incidents that we should expect to see trending in 2020.
This experience has influenced the way that we develop our own food safety prediction machine.
Here’s the deal:
I will walk you through the core principles behind our approach. Please let me know your feedback by dropping me a line to nikosm@agroknow.com.

Choose your problem right
What is the question that you are trying to answer? Which are the important dimensions that you want to explore? Which are the corresponding hypotheses that you are trying to confirm in a statistically significant manner?
In our GFSI experiment, we were looking for answers in three questions related to prediction:
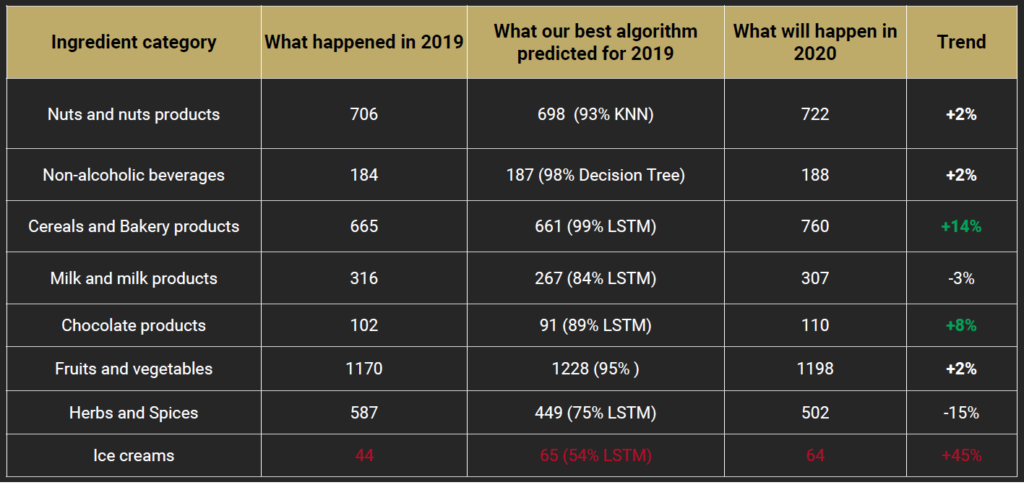
- In which ingredient categories should we expect more food safety incidents in 2020?
- What types of food safety hazards should we expect to see more during the next 12 months?
- If we focus on a particular product category, such as chocolate products, which are the most vulnerable ingredients and emerging food safety issues that we should expect?
Question #1 refers to “food safety incidents”. We refer to two types of incidents: food product recalls and food border rejections (i.e. import refusals).
Practically, it asks:
- Given that I have access to historical data about all food product recalls and border rejections that have taken place until December 2019, classified according to the raw materials and ingredients that were linked to the recall…
- …is it possible to predict with high confidence how many food safety incidents we are going to have for each ingredient category in 2020?
Here is the table presenting the ingredient categories we should expect product recalls & border rejections to increase during 2020.
Use the data that makes sense for this problem
Which are the data subsets that it makes sense to use for each one of the important questions?
For instance, focusing on Question #1, we need as much historical data about food product recalls and border rejections. Still, there are some data selection decisions to take:
- Are we interested in the global picture, using a very large global data set to build a generic food safety predictor?
- Or do we need a subset of the data only associated with specific geographical regions of interest, such as the United States or the European Union?
- Furthermore, should we slice the data according to the product categories that they refer to, removing irrelevant product recalls and rejections so that they do not influence the prediction?
So we went for it:
In our experiment, we decided to explore all possible options. We wanted to see what the global data set can help us predict about all types and locations of food safety risks. We also focused on the chocolate products and their ingredients, creating a subset that included all chocolate product recalls and border rejections.
This gave us plenty of data variations to play with.

Get ready for some serious data preparation, splitting and re-combination work
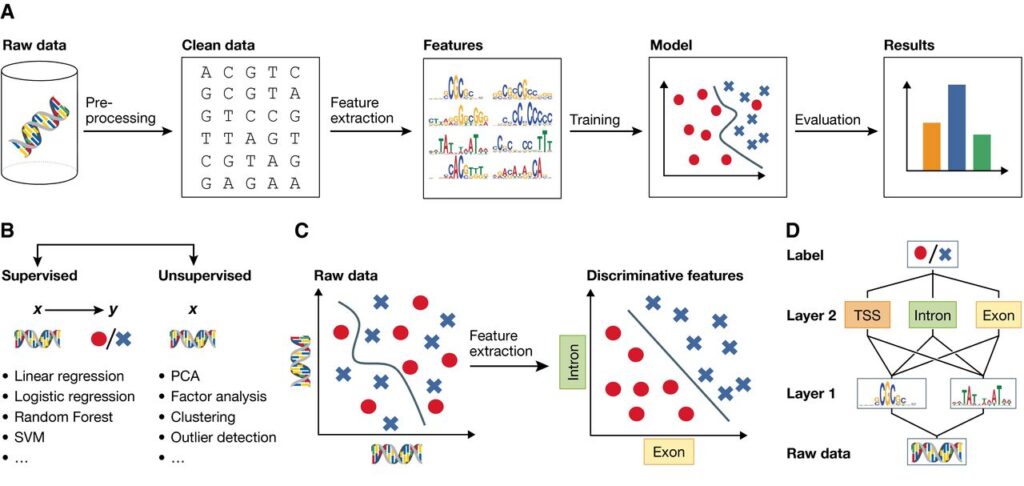
Simply put, AI algorithms are trying to build a mathematical model, either before the system is deployed in real settings or during the time of operation.
For instance, supervised machine learning builds a model that makes predictions based on evidence in the presence of uncertainty. A supervised learning algorithm takes a known set of input data and known responses to the data (output). Then, it trains a model to generate reasonable predictions when unknown data comes.
This is typically done by splitting the real, historical data into training and testing subsets: the algorithm is parameterized using the training data, then its predictive capabilities are evaluated using the testing data.
How do we generate reliable predictions?
There are several data preparation and combination techniques to ensure that the model will be able to produce reliable predictions. These include multiple data splitting and cross-validation techniques, as well as ways to ensure that the train and test data distributions are similar. Then, data problems such as handling missing or inconsistent data comes to play. Again, there are plenty of techniques to help address e.g. missing data values.
Depending on the techniques to be used, input data may need to be further categorized or separated into specific groups or classes (classification techniques); or to be formulated into data ranges and real numbers, such as the probability of an incident happening (regression techniques).
What’s the bottom line?
There is going to be some serious data processing and management that needs to take place, before we can deploy algorithms.

Now:
It is fine to perform a one-off data preparation task when you aim at a scientific experiment or study. However, in order to deliver a reliable and efficient food safety prediction service, the way that input data is continuously going to be processed, managed and combined, needs to be taken into serious consideration.
For our experiment, we already have the historical data sets in our data platform that offers a number of advanced data management and manipulation features. For each algorithmic experiment, the original data sets have been split into different versions of input data, which have been stored in separate data formats and locations.
But here’s the kicker:
In this way, we have generated multiple subsets, versions and combinations of the same historical data.
Use as many AI algorithms as you can over all these data combinations
How can one find and parameterize the algorithm that will work best for a specific problem and data combination? Well, by extensive testing and parameterization. This means, trying as many algorithms and variations as you can.
For our GFSI prediction talk, we worked with 4 different families of supervised machine learning algorithms and one family of deep learning algorithms. We had to try different parameters for each algorithm, execute different passes over the input data to see what type of prediction models were built, refine and revise and re-run again.
Surprisingly:
The algorithm that performed better has not been the one that we have originally expected to do so.
An experimentation panel within our data platform helped us schedule and automate the execution of many of these tasks. Having the algorithms already implemented as platform components, made it possible to execute each variation over different data combinations, until we found which were the right data sets per algorithm type.
We therefore ran two complete iterations: one producing predictions based on the global food incident data set; and one using the data specifically about chocolate products and ingredients.
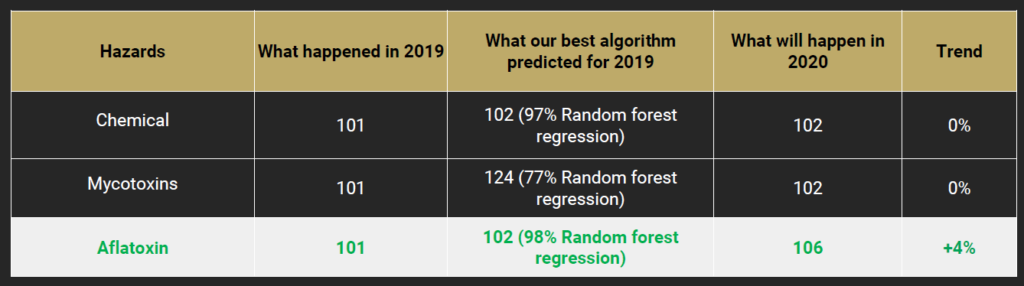
What kind of results did we get for critical ingredients used in chocolate products?
An example is in the table that follows showing food safety hazard predictions for peanuts. The algorithm is over 98% confident that in 2020 aflatoxin incidents will continue.
Focus on the right prediction metrics
How can we measure if a prediction algorithm is working properly? There are so many metrics that one can use. Which makes it very important to choose the right ones for the prediction problem at hand.
One may use classic information retrieval and classification metrics such as Precision and Recall. Or other simple machine learning metrics that measure the accuracy and coverage of an algorithm. Ideally, the selection of the evaluation metrics should be linked to the formulation of the problem at hand.
It should also reflect the real settings in which the algorithm is expected to operate.
I can think of scenarios where the classification accuracy of an algorithm needs to be high. For instance, in the case of a prediction system that suggests whether lab testing of specific products or for specific hazards should take place.
Taking the wrong decision means that:
- unnecessary (and expensive) lab tests will take place for a raw material or hazard that we shouldn’t be really looking for
- or we will miss performing a test for an important emerging hazard, and it may go unnoticed under our food risk monitoring procedures
In our GFSI experiment, we were more interested in coverage than accuracy. That is, we wanted to understand incident trends and therefore were looking for a numerical prediction: what is the number (#) of food safety incidents we should expect in 2020?
Having an inaccurate prediction was not critical in our scenario: we were more interested in uncovering the trends.
On the other hand, good coverage was critical. Not being able to calculate a prediction for one or more product categories would mean that we would have no clue about what to expect during the next 12 months.

Think about operations
There’s a number of questions that need to be answered when assessing operations. How often should such an extensive experimentation process take place? When should we use new data and compare the selected algorithm with other options? If necessary, how can a model be re-trained or re-parameterized?
What about the expert knowledge that comes from the users? How can human experience and real-life expertise feed the prediction model, by correcting or validating predictions? How does the algorithm incorporate such input?
How should the prediction outcomes be visualized so that they can become more comprehensive and relevant to the food risk monitoring and prevention tasks that they are meant to support? Which are the visual dashboards and interface modalities that can be used? How do users respond to each visualization and what do they find more useful and usable?
And so it goes.
This is why our team is devoting its full attention and energy at this phase.
We have done the experimentation part. We have used a variety of data combinations. We have selected the prediction algorithms fit for each client case.
Now we will work on the prediction dashboards, integrating our food safety risk monitoring and prevention software.
We are providing a predictions dashboard that is seamless and makes perfect sense for our users.
If you’d like to discover how FOODAKAI can help your Food Safety & Quality team prevent product recalls by monitoring & predicting risks, schedule a call with us!